Data Warehouse API
FinBIF Data Warehouse contains 60M+ occurrences and this page tells how to query occurrence data and how to get started with sharing occurrence data with us, as well as description of the overall architecture of the service.
Architecture
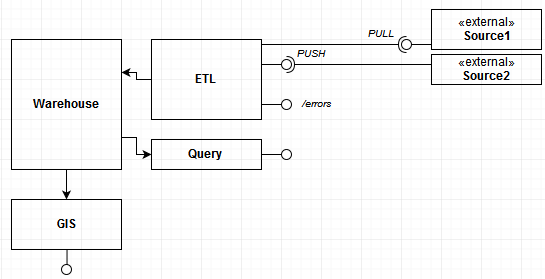
FinBIF Data Warehouse (later DW) consists of the following components:
- Big-data search engine (Vertica) – the hearth of the DW
- ETL components for receiving and storing incoming data (ETL = Extract, Transform, Load)
- A HTTP API (api.laji.fi) for queries
- GIS services attached to the DW
- QGIS Plugin and R-package for using the Query API
Getting data into the DW
- /push – api.laji.fi/datawarehouse/push is always waiting to receive occurrence data from external sources (push).
- Custom solutions. We can always implement custom solutions for reading occurrence data, for example directly from a database connection you provide to us.
- Manually upload your occurrence data as secondary data to FinBIF for example in text-, Excel- or Geopackage -format (todo: Shape- or MapInfo-format) via Data Bank.
Read more: Checklist for starting data transfer
For mature IT-systems, we would highly recommend the /push API. It is completely independent from any FinBIF logic and leaves all responsibility for transferring inserts, updates and deletions to the external source.
Push approach requires the external service to implement the Transaction-API exactly as we have specified. It can be technically challenging to implement.
For both cases, push and pull, the final data format can be almost anything. We have documentation about currently supported data formats.
For custom solutions, we plan together how your data fits to FinBIF DW data model. Also for manual upload, we take care of transforming the files you upload to DW format.
Data model
FinBIF data model for occurrence data (used by Vihko Notebook, described in schema.laji.fi) is the following:
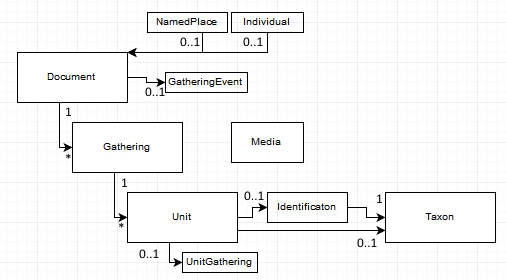
- Document – Metadata about the batch of occurrences (collection id, source id, created date, modified date, creator, owners, etc.)
- GatheringEvent – Data shared by all gathering events, for example background variables of different observation schemes.
- Gathering – Gathering event happens in some time at some place by some persons.
- Unit – Occurrences recorded during the gathering event.
- Identification – Identifications (possibly done later).
- Media – Image, audio. Documents, Gatherings and Units can have 0..* media. Document level media are for example images of specimen labels. Gathering level media are about the location/habitat. Unit media are about the occurrence.
- NamedPlace – For example an observation scheme area, that is surveyed across many years.
- Individual – For example a ringed bird.
Data warehouse data model expands the above. It is also optimized for searches.
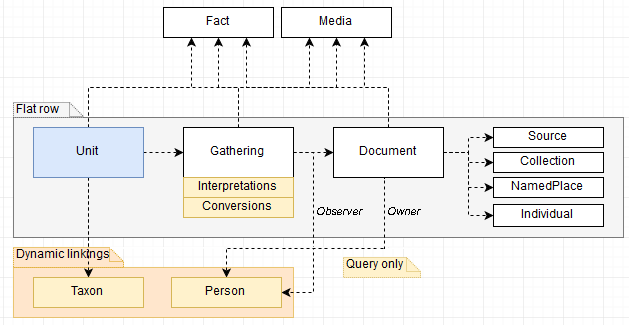
- Each Document is received from a Source end belongs to one Collection (dataset).
- Gathering.Interpretations – Gathering-level spatial data is used to interpret geographic information; for example if the source does not provide coordinates but does provide a name of the municipality, we interpret the coordinates from the municipality.
- Gathering.Conversions – We convert coordinates to several coordinate systems and calculate date fields (day of year, etc).
- Fact – Document, Gathering and Unit can have 0..* facts. These are key-value pairs (more below).
- Taxon – FinBIF taxon concept (more below).
- Person – FinBIF user (more below).
- Annotation – (missing for the image). Each unit and document can have 0..* annotations. Annotations are information that do not come from the original source, but have been recorded in FinBIF and attached to the occurrence. For example a taxon expert and provide a different identification than is recorded in the original source.
- Unit.Quality – Information about interpret quality of the occurrence based on the source, annotations, automated quality control, etc.
- Unit.Interpretations – Identification based on possible annotation information. Interpreted individual/pair count.
When transferring data to the data warehouse, interpretations, conversions and dynamic linkings are not provided, they will be calculated in FinBIF.
FinBIF data warehouse data model does not include every single field and variable of every dataset. Only the most relevant fields have been selected, for example time, coordinates, taxon, life stage, etc. The aim is to harmonize this data across all the different datasets, so that these data from every source is usable and searchable in the same format in FinBIF. Rest of the fields are stored as key-value pairs (Facts) using the exact variable name and value that was provided by the original data source.
Taxon is a taxon concept defined in FinBIF taxon database, usable by /taxa endpoint of the API. Every night the data warehouse decides how occurrences are linked to the taxonomy. This is done based on the reported taxon id or the verbatim taxon name (scientific name, vernacular name, etc).
User identifiers of document creators, owners and gathering level observers are each night linked with the user data in FinBIF person database. We do not link plain names, only user identifiers. The aim is to allow the users to search their “own observations” and “the observations they have stored” across different source systems, by linking the user ids to a same FinBIF person.
Read more: Data warehouse fields.
Query API
Api.laji.fi provides endpoints to query public and private data stored to FinBIF data warehouse. To access private data, the access token of the application must have been given permissions to do so and signing a data use agreement.
Unit level is the most commonly needed in queries (querying individual occurrences). The same filters can be used with all the endpoints, but parameters vary. Because of the nature of our big-data search engine (Vertica), aggregate queries are often more performant than list queries. If your data need can be defined using aggregating occurrences instead of listing occurrences, use the aggregate query.
- query/unit/count – The count of occurrences that match the filters.
- query/unit/list – selected fields, sorting and paging parameters are provided
- query/unit/aggregate – aggregateBy, sorting and paging parameters are provided
- /document endpoint returns the entire contents of a single document.
The following are also available
- query/annotation/aggregate|list
- query/unitMedia/list
- query/document/aggregate
- query/gathering/aggregate
Finally there are /statistics endpoints for occurrences (units) and gatherings. They are customized versions of the aggregate endpoint that read their data from the private data warehouse (instead of public). Statistics endpoints have limited filter and aggregateBy parameters (limited to those that can not be used to reveal too much info about locations of sensitive species). The purpose if these endpoints is to provide statistics to observation scheme result pages, and to show information on species cards, that, if done from the public warehouse, would show erroneous numbers, because the public data is restricted/coarsed for certain species/observation schemes.
The following endpoints may be useful when creating an user interface/output for warehouse data:
- EnumerationLabels – Descriptions of enumerations used in documents and filters in three languages.
- Filters – Descriptions of the filters in three languages, including enumeration descriptions. For filters that take in resource ids as parameters, the name of the resource in api.laji.fi is provided.